Just a note for this sharing session.
Big Data at Google
Speaker: Apurva Desai
Apurva Desai has over 20 years of experience in building software and managing teams. He has been with early stage startups to big sized companies. He has been focused on cloud, big data and distributed computing for the last 10+years starting with Yahoo where his team was responsible to manage 20k+ nodes of Hadoop and provide solutions to internal projects migrating to Hadoop ecosystem. At Pivotal Software, a spinoff of EMC, his team built and commercialized Pivotal’s Hadoop distribution. Most recently he managed Motorola’s mobile phone experiences powered by mobile cloud backend running on GCP. Apurva earned his Bachelor’s of engineering from University of Mumbai, India and Master of engineering from Simon Fraser University, Canada
What does Cloud 3.0 look like?
- Cloud 2.0 (Assembly Required)
- VMs
- Object Store
- Databases
- Networking
- Cloud 3.0
- Containers
- Messaging
- NoSQL
- Big Data
Complixities of Big Data Processing
- Programming
- Resource provisioning
- Handling growing scale
- Reliability
- Deployment & Configuration
- Utilization improvements
- Performance tuning
- Monitoring
But what you should do is focusing on programming and dig your data.
10+ Years of Tackling Big Data Problems

- GFS (2002 ~ 2004)
- MapReduce (2004 ~ 2005)
- Dataflow (GCP)
- BigTable (2005 ~ 2006)
- Apache HBase
- Hadoop
- Bigtable (GCP)
- Dremel (2006 ~ 2008)
- Apache Drill
- BigQuery (GCP)
- PubSub (2008 ~ 2010)
- Pub/Sub (GCP)
- FlumeJava (2010 ~ 2012)
- Apache Crunch
- MillWheel (2012 ~ 2014)
- Apache Beam
- Dataflow (GCP)
- Apache Beam
- TensorFlow (2014 ~ now)
"Google is living a few years in the future and sending the rest of us messages." - Doug Cutting, Hadoop Co-Creator
Bridging the Waves

- Capture
- Cloud 3.0
- Pub/Sub
- Logs, App Engine
- BigQuery streaming
- Cloud 2.0
- Rabbit MQ
- Kafka
- Cloud 3.0
- Store
- Cloud 3.0
- Cloud Storage (objects)
- BigQuery Storage (structured)
- Cloud Bigtable (NoSQL HBase)
- Cloud Datastore (NoSQL)
- Cloud 2.0
- Cassandra
- HBase
- MongoDB
- Cloud 3.0
- Process
- Cloud 3.0
- Cloud Dataflow (stream and batch)
- Cloud Dataproc
- Cloud 2.0
- Hadoop & Ecosystem
- Spark
- Hive
- Hadoop & Ecosystem
- Cloud 3.0
- Analyze
- Cloud 3.0
- BigQuery (large scale SQL)
- Cloud Machine Learning
- Cloud 2.0
- Hadoop & Ecosystem
- Spark
- Hive
- Hadoop & Ecosystem
- Cloud 3.0
- Visualize
- Cloud 3.0
- Cloud DataLab (Python/Jupyter Notebook)
- Cloud 2.0
- Tableau
- Qlik
- Cloud 3.0
Reference Architecture
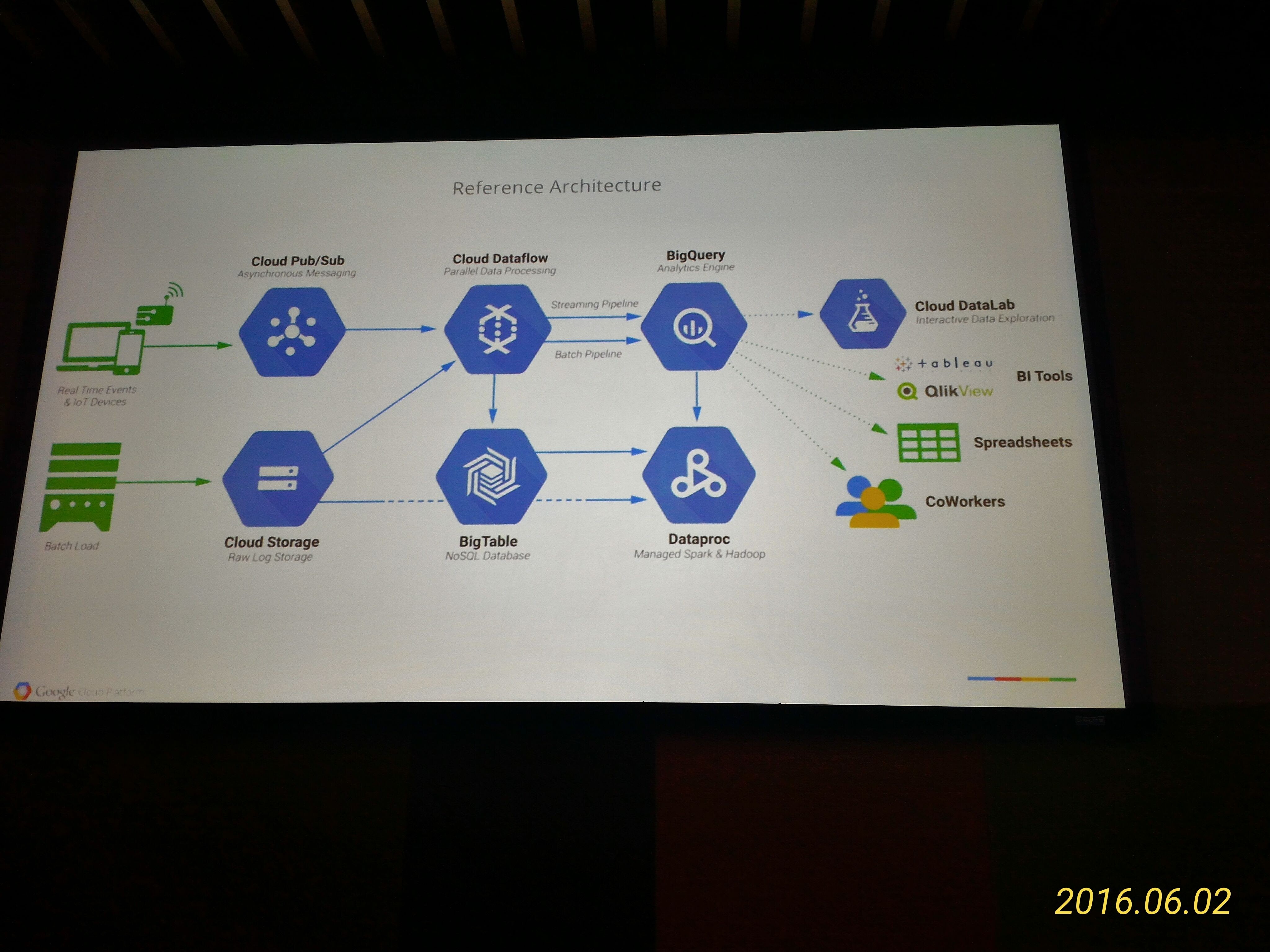
Apache Beam and Google Cloud Dataflow
- Dataflow
- API Interface (SDK)
- Dataflow model / Beam model
- You can write you own sdk with any language
- API Interface (SDK)
- Apache Beam
Beam vs Spark
- Classic Batch Processing
- Simillar
- Windowing
- Beam
- Window
- Sum
- Spark
- Window & Sum
- Beam
- Late Data
- Beam is more easy to implement in this part
- Sessions
Google Cloud Dataflow
- Fully-managed and auto-configured
- Auto graph-optimized for best execution path
- Autoscaling mid-job
- Dynamic Work Rebalancing mid-job
- Fault Tolerant execution of Beam pipelines
Dataproc - Managed Hadoop + Spark
- Start a massive Hadoop or Spark cluster in 90 seconds
- Pre emptible VMs at 30% of othe cost, Custom VMs
- Per-minute billing
- Separation of Storage + Compute
- Incredibly fast networking
Ephemeral clusters - jobs before clusters
- Deploy Cluster
- Submits jobs
Separation of Storage and Compute
- Based on your use cases
BigQuery
Fun BigQuery Stats
- Largest query by rows => 10.5 Trillion rows
- Larget query by data size => 2.1 PB
- Largest storage customer => 62 PB
- Streaming per second => 4.5 million
BigQuery - explained
- We just rented ~9000 cores from Google for ~30 seconds
- We only paid $20
- Most importantly, it's hide from end users.
- Users do not thins about cores.
What is BigQuery?
- Serveless, Fully Managed, No-Ops Data Warehouse
- Petabyte-Scale and Fast
- Convenience of SQL
- Externalization of Google Dremel
Cloud Pub/Sub - Asynchronous Messaging
- A FULLY-MANAGED GLOBAL Publish and Subscribe service (a many-to-many queue)
- Seamlessly scales to 1,000,000+ QPS
- Guaranteed durable at-least-once delivery
- 7-day message acknowledgement window
- Simple REST API makes it portable
References
Case study: Spotify's Event Delivery System
Speaker: Jelena Pješivac-Grbović
Dr. Jelena Pješivac-Grbović is a staff software engineer in Cloud at Google, in Mountain View, CA. She is the lead for MapReduce and one of the leads of the Google Cloud Dataflow project. Jelena's research interests include large-scale data processing, distributed, and cloud computing. She is an active member of IEEE, ACM, and SWE.
Introduction
其實就是把 References 那三篇稍微帶過這樣。
- Event Delivery System
- High QPS
- ~700K events/sec in peak
- High QPS
References
- Spotify’s Event Delivery – The Road to the Cloud (Part I) | Labs
- Spotify’s Event Delivery – The Road to the Cloud (Part II) | Labs
- Spotify’s Event Delivery – The Road to the Cloud (Part III) | Labs
附上一張到此一遊照 (?)
Share
Donation
如果覺得這篇文章對你有幫助, 除了留言讓我知道外, 或許也可以考慮請我喝杯咖啡, 不論金額多寡我都會非常感激且能鼓勵我繼續寫出對你有幫助的文章。
If this blog post happens to be helpful to you, besides of leaving a reply, you may consider buy me a cup of coffee to support me. It would help me write more articles helpful to you in the future and I would really appreciate it.
Related Posts
- CPB200: BigQuery for Data Analysts
- Make Google Cloud CDN serve gzip compressed content for Nginx server
- GCPUG.tw #27
- GCPUG.tw #28
- CP100A: Google Cloud Platform Fundamentals